蜜蜂采集器的使用教程 - 获取意大利米兰家具展览会参展商企业名录
本文以意大利米兰家具展览会参展商企业名录采集为例,介绍网址采集中的POST翻页采集方法、JSON数据解析方法以及如何发布到Excel文件。
网址采集
数据来源:意大利米兰家具展览会官网。
使用浏览器打开意大利米兰家具展览会官网,转到“Exhibitors List”,按F12打开浏览器的开发者工具。可以看到.../exhibitorSearch这样的POST请求,返回内容为JSON格式。这个请求网址和原始网址有很大不同,进一步跟踪分析,可以发现,网址是在sdm-breakout-config.bundle.js文件中组装而来,是亚马逊云amazonaws的网址。简单起见,我们直接使用这个AWS网址就可以了。
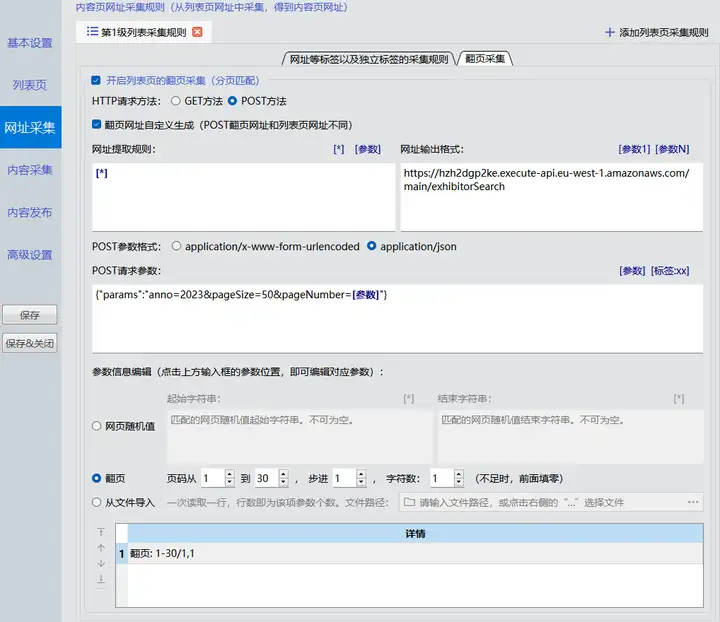
进一步分析这个.../exhibitorSearchPOST请求的参数,发现是JSON格式的参数。由于采集器不直接支持这种较复杂的请求参数,所以,我们网址采集时,首页设置为空页或任意页,然后将翻页地址设置为.../exhibitorSearch,实际采集时只采集翻页。如下:
网址采集翻页设置
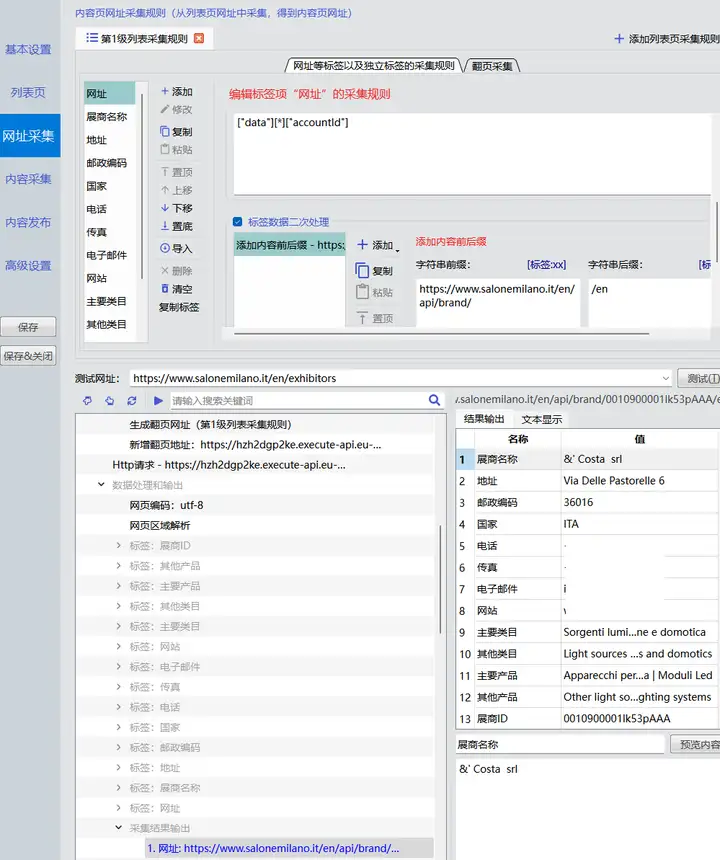
网址采集中的各标签采集规则如下:
网址:提取方式为JsonPath,JsonPath提取规则:["data"][*]["accountId"];添加标签数据二次处理项“内容前后缀”,前缀为.../en/api/brand/,后缀为/en;
展商名称:提取方式为JsonPath,JsonPath提取规则:["data"][*]["nomeEspositore"];添加标签数据二次处理项“字符串替换”,将null替换为空,因为这里会出现null值;
地址:提取方式为JsonPath,JsonPath提取规则:["data"][*]["indirizzo"];同上,替换掉null;
邮政编码:提取方式为JsonPath,JsonPath提取规则:["data"][*]["cap"];同上,替换掉null;
国家:提取方式为JsonPath,JsonPath提取规则:["data"][*]["nazioneIso3AlphaCode"];同上,替换掉null;
电话:提取方式为JsonPath,JsonPath提取规则:["data"][*]["telefono"];同上,替换掉null;
传真:提取方式为JsonPath,JsonPath提取规则:["data"][*]["fax"];同上,替换掉null;
电子邮件:提取方式为JsonPath,JsonPath提取规则:["data"][*]["email"];同上,替换掉null;
网站:提取方式为JsonPath,JsonPath提取规则:["data"][*]["sitoInternet"];同上,替换掉null;
主要类目:提取方式为JsonPath,JsonPath提取规则:["data"][*]["categorieI"];同上,替换掉null;
其他类目:提取方式为JsonPath,JsonPath提取规则:["data"][*]["categorieE"];同上,替换掉null;
主要产品:提取方式为JsonPath,JsonPath提取规则:["data"][*]["prodottiI"];同上,替换掉null;
其他产品:提取方式为JsonPath,JsonPath提取规则:["data"][*]["prodottiE"];同上,替换掉null;
展商ID:提取方式为JsonPath,JsonPath提取规则:["data"][*]["accountId"];同上,替换掉null;
其中,我们点击某一个企业,抓取其网络请求,可以看到,实际请求的地址是“.../en/api/brand/0010900001lk53pAAA/en”,“0010900001lk53pAAA”为展商ID。所以,内容网址通过以上方式拼接。
网址采集的标签规则与采集测试
内容采集
网址采集中拼接了网址标签,这个网址返回的内容也是JSON格式。访问后,可以看到,返回的内容里面有个url,也就是点击“Visit brand page”按钮后跳转的页面,页面是企业展示页,具体内容就是这个“.../en/api/brand/0010900001lk53pAAA/en”里面的内容,只不过是转换为HTML格式了。这里,如果直接使用“.../en/api/brand/0010900001lk53pAAA/en”里面的内容也是可以的,但不方便浏览。
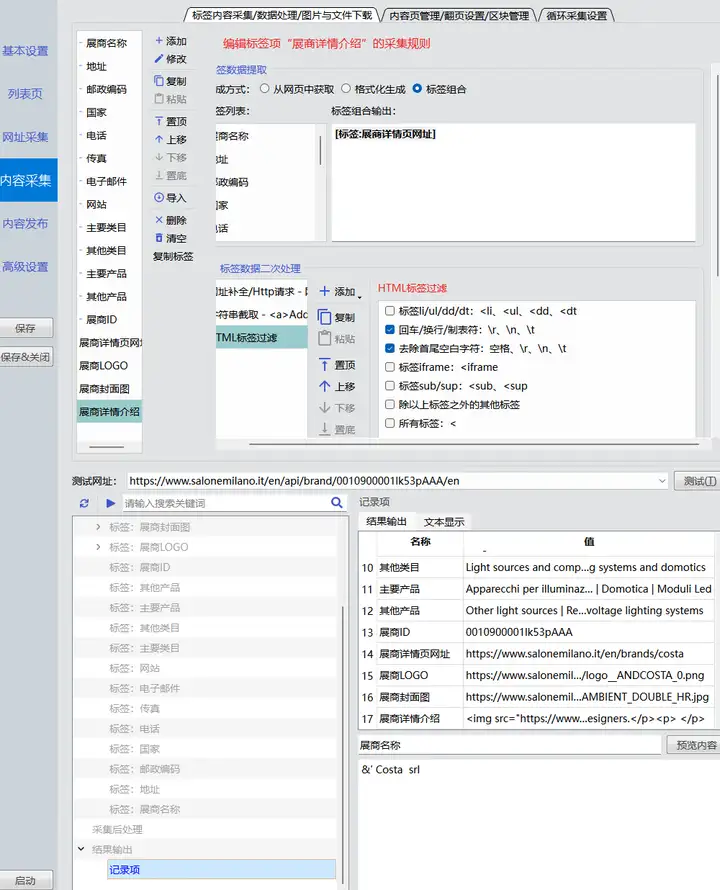
内容采集中的各标签采集规则如下:
展商详情页网址:提取方式为JsonPath,JsonPath提取规则:[0]["url"];
展商LOGO:提取方式为JsonPath,JsonPath提取规则:[0]["field_logo_export"]["url"];
展商封面图:提取方式为JsonPath,JsonPath提取规则:[0]["field_cover_export"]["url"];
展商详情介绍:标签组合:[标签:展商详情页网址];添加标签数据二次处理项“网址补全/Http请求”;添加标签数据二次处理项“字符串截取”,起始字符串为<a>Add to bookmarks</a>,结束字符串为</article>;添加标签数据二次处理项“HTML标签过滤”,过滤掉div、首尾空白、回车换行;添加标签数据二次处理项“HTML标签过滤”,过滤掉div、首尾空白、回车换行;
至此,采集规则基本完成。
但是,采集过程中发现部分网址重复,因为不少展商没有企业展示页(内容页网址为空),所以,这里要在高级设置中去掉“重复网址检测”的勾选。
此外,基本设置的采集时间间隔改为5000毫秒以上,否则可能被防火墙阻止,导致返回500错误码。
内容采集的标签规则与采集测试
内容发布
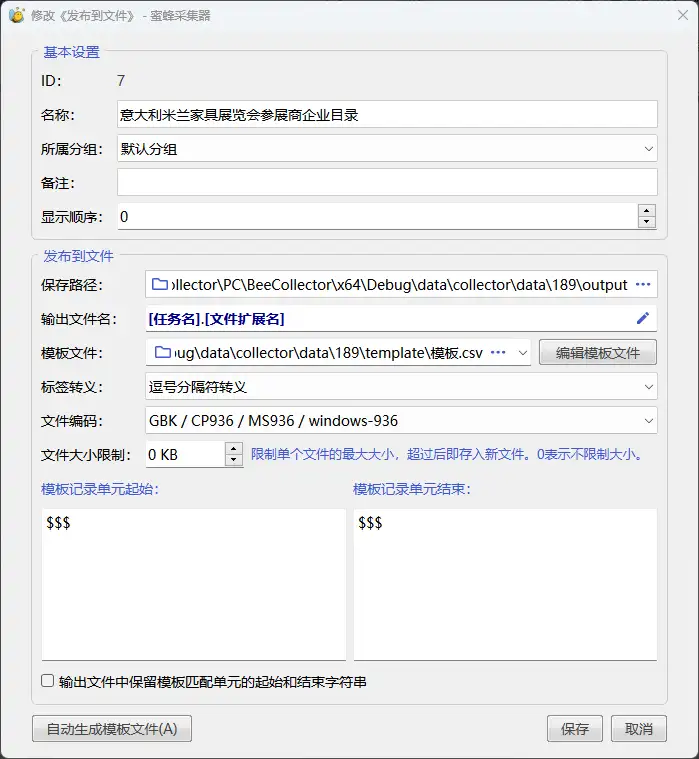
打开主菜单“发布”——“发布到文件”,添加一项“意大利米兰家具展览会参展商企业名录”,设置保存路径和模板路径(csv后缀),输出文件名为[任务名].[文件扩展名],文件编码为GBK。
“发布到文件”配置
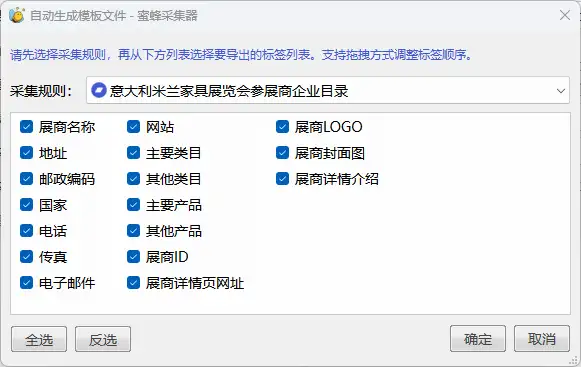
点击“自动生成模板文件”,选中刚刚新增的采集规则,选中所有标签,点击“确定”。
自动生成模板文件
至此,生成了输出模板,并设置好了发布配置。
在采集规则的内容发布中,添加发布通道“发布到文件”,并选择刚刚添加的发布配置。至此,完成了采集和发布的设置。
任务运行
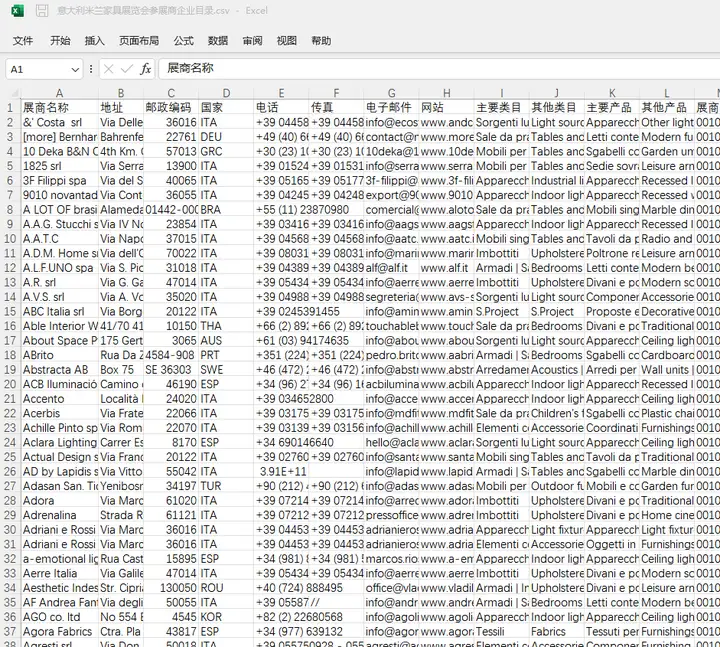
运行任务。以下是采集结果展示:
采集结果展示
至此,就实现了意大利米兰家具展览会参展商企业名录的采集。更多内容,请参考相关的视频教程。




 发表于 2023-4-24 23:05:30
发表于 2023-4-24 23:05:30