本文以微博评论的采集为例,简单介绍一下数据采集的分析思路,以及JSON数据的解析、发布到文件的文件模板编写等。
环境准备VSCode: 全称Visual Studio Code,是微软公司开发的一款跨平台文本编辑器,支持多种语言和文件格式的编辑。下载地址:点击下载 蜜蜂采集器: 一款数据采集软件。 页面分析使用浏览器打开微博热搜榜,打开其中一个热搜,进入后找到其中一个评论较多的微博文章页面(复制微博地址到新标签页中打开)。按F12打开浏览器的开发者工具。刷新页面,并不断下拉加载更多评论,再分析“开发者工具”的“网络”请求列表,可以看到,.../ajax/statuses/buildComments?is_reload=1&id=4881689485248284&is_show_bulletin=2&is_mix=0&count=10&uid=164233442351362这样的的请求,即为评论内容列表,如下:
.../ajax/statuses/buildComments?is_reload=1&id=4881689485248284&is_show_bulletin=2&is_mix=0&count=10&uid=164233442351362.../ajax/statuses/buildComments?is_reload=1&id=4881689485248284&is_show_bulletin=2&is_mix=0&max_id=519022693544123&count=20&uid=164233442351362.../ajax/statuses/buildComments?is_reload=1&id=4881689485248284&is_show_bulletin=2&is_mix=0&max_id=169377995911471&count=20&uid=164233442351362.../ajax/statuses/buildComments?is_reload=1&id=4881689697851153&is_show_bulletin=2&is_mix=1&fetch_level=1&max_id=0&count=20&uid=164233442351362.../ajax/statuses/buildComments?is_reload=1&id=4881689697851153&is_show_bulletin=2&is_mix=1&fetch_level=1&max_id=145601057508382&count=20&uid=164233442351362
以上五个地址分别为:刷新微博文章页面时初次加载的评论,共10条;下拉加载更多评论20条,两次;点击展开二级评论回复,共20条;二级评论回复页面下拉加载更多评论20条。其中,uid等涉及用户隐私的信息,这里都替换成虚假的。
再看网址请求参数。
- is_reload参数,改为0的情况下请求一次,发现加载了完整的HTML页面。可见,is_reload即为是否继续加载,为1表示仅加载评论内容,为0则带上HTML页面完整内容。
- id参数。对比刷新微博文章页面和展开二级评论回复的情况,可见id是文章或回复的记录编号。也可以推测,对于微博的后端数据库设计,评论和微博文章都是在一个数据表中的。
- flow参数。点击评论的“按热度”、“按时间”排序,进而得出,flow参数为1表示按时间排序,为0表示按热度排序。
- is_show_bulletin参数。分别改为0、1、2,返回结果长度和内容都有很大不同,且似乎排序也不一样,暂不清楚具体用途。
- is_mix参数。也不清楚用途。
- count参数。记录条数,微博页面初次加载10条,其余情况为20条。但实际修改此参数,发现无效,返回记录始终是20条。
- max_id参数。这里应该是上一次加载的评论的最大id。初次加载时此值为0,可以不填。
- fetch_level参数。为1时表示获取二级评论列表。
- uid参数。这是看起来最不重要,实际最关键的参数。uid即当前微博的博主的用户ID。而二级评论也是这个博主的UID,并不是评论者的UID。可见,uid在微博服务器后端的实现逻辑,相当于一个key。微博评论显然数据量庞大,如果所有的评论放一个数据表,显然不行,效率极低。我们假设微博评论后台数据库设计中,以UID为key,将若干用户的评论放到一个数据库中,则查询方便很多。当然实际情况可能并非如此,可以使用了redis,也可能双份冗余存储评论,这里我们姑且这样假设,以便理解这里的各个参数。
看一下评论的具体内容:
{ "created_at": "Tue Mar 21 11:23:04 +0800 2023", "id": 4881689623497850508, "rootid": 4881689623497850508, "rootidstr": "4881689623497850508", "floor_number": 552, "text": "晚上见", "disable_reply": 0, "restrictOperate": 0, "source_allowclick": 0, "source_type": 4, "source": "来自广西", "user": { "id": 6878152332420, "screen_name": "只动233434356速度", }, "mid": "4881689623497850508", "idstr": "4881689623497850508", "url_objects": [], "liked": false, "readtimetype": "comment", "analysis_extra": "author_uid:164233442351362|mid:4881689485248284", "match_ai_play_picture": false, "comments": [], "max_id": 0, "total_number": 61, "isLikedByMblogAuthor": false, "like_counts": 3372, "more_info": { "scheme": "sinaweibo://detailbulletincomment?comment_id=4881689623497850508&is_show_bulletin=2", "user_list": [ ], "text": "等人 共61条回复", "highlight_text": "共61条回复" }, "text_raw": "晚上见" },
我们需要提取以下参数:
- created_at: 评论时间
- id: 评论ID
- floor_number: 评论楼层
- source_type: 地域类型
- source: 地域
- text_raw: 文本内容
- text: HTML文本内容
- user.id: 用户ID
- user.screen_name: 用户昵称
- like_counts: 点赞数
- total_number: 回复条数
对于翻页地址的提取。需要提取最后一条评论的id,然后拼接出翻页网址。
对于二级评论的提取。由于采集器的规则并不适合二次评论的采集,所以,我们只能使用折中的办法。采集一级评论,并将一级评论的二级地址写入到本地文件中,然后在另外一个类似的采集规则中,读取这个地址列表,再去采集二级评论,基本上就可以了。
采集规则实现由于存在两条采集规则,这里新建一个采集分组“新浪微博评论采集”,把采集规则都放到这个分组中。
新建一个采集规则“新浪微博评论采集1”。列表页地址使用普通网址“.../164233442351362/Myh7em1jK”,点击下方“实时输出”窗口的网址,在弹出菜单中选择“测试网址采集”。调试区的内容可以看出,获取内容不对,302错误,Location为登录地址。这说明需要设置Cookie。我们打开Cookie管理中,添加Cookie项目。再次测试,获得数据。
但实际内容都是一些网页代码,没有需要的数据。我们目前需要从“.../164233442351362/Myh7em1jK”生成“.../ajax/statuses/buildComments?is_reload=1&id=4881689485248284&is_show_bulletin=2&is_mix=0&count=10&uid=164233442351362”这样的网址,也就是需要id。
因此,在浏览器的开发者工具中,继续分析,发现“.../164233442351362/Myh7em1jK”最终加载了“.../ajax/statuses/show?id=Myh7em1jK”地址。而“.../ajax/statuses/show?id=Myh7em1jK”地址的内容为json格式,里面有id和uid等数据,足够了。
回到采集规则中,将普通网址改为“.../ajax/statuses/show?id=Myh7em1jK”,再次“测试网址采集”。
网址采集中,添加标签“用户ID”,解析方式为JsonPath,采集规则为["user"]["id"];添加标签“微博ID”,解析方式为JsonPath,采集规则为["id"]。标签“网址”中,解析方式为通配方式匹配,提取规则为},输出格式为.../ajax/statuses/buildComments?is_reload=1&id=[标签:微博ID]&is_show_bulletin=2&is_mix=0&count=10&uid=[标签:用户ID]。其中,提取规则的最后面有个},这样就可以一直匹配到最后一个字符,否则可能出现空记录。再次“测试网址采集”,结果正确。
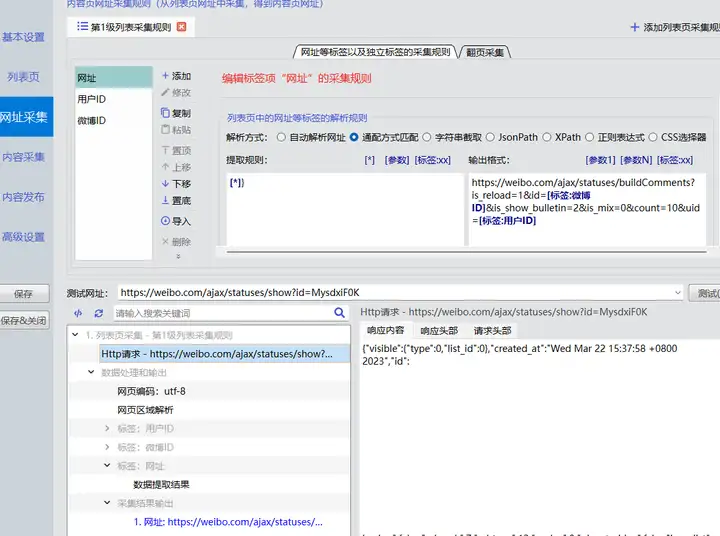
网址采集
内容采集。解析方式为JsonPath。如下:
- 时间: ["data"]
- ["created_at"]
- 楼层: ["data"]
- ["floor_number"]
- 评论ID: ["data"]
- ["id"],此项需要勾选“标签内容不得重复”,因为评论列表网址可能重复被请求。
- 地域类型: ["data"]
- ["source_type"]
- 地域: ["data"]
- ["source"]
- 内容: ["data"]
- ["text_raw"]
- HTML内容: ["data"]
- ["text"]
- 回复者ID: ["data"]
- ["user"]["id"]
- 回复者昵称: ["data"]
- ["user"]["screen_name"]
- 点赞数: ["data"]
- ["like_counts"]
- 回复数: ["data"]
- ["total_number"]
时间标签处理。时间标签的值,如上方例子,结果为"Tue Mar 21 11:23:04 +0800 2023",这种时间不利于后续处理,转化为“2023-03-21 11:23:04”这样的格式较好。添加“标签数据二次处理”——“内容转换:简繁/拼音/时间”,选择“时间字符串转时间戳”,时间格式字符串可以设置为ddd MMM d HH:mm:ss +0800 yyyy;再次添加“标签数据二次处理”——“内容转换:简繁/拼音/时间”,选择“时间字符串转时间戳”,时间格式字符串可以设置为yyyy-MM-dd HH:mm:ss。
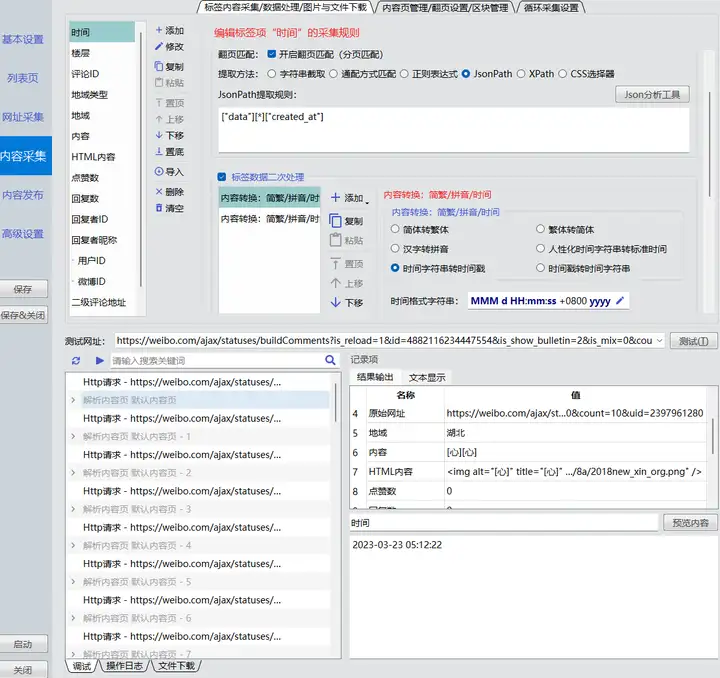
内容采集
翻页采集如上面分析,翻页地址为“原始地址”+“&max_id=...”。而max_id的值在JSON的最后面。因此,开启翻页采集。选择“前后页”模式,起始字符串“"rootComment"”,结束字符串“"trendsText"”,提取规则为“"max_id":[参数],”,网址输出格式为“[标签:网址]&max_id=[参数1]”。
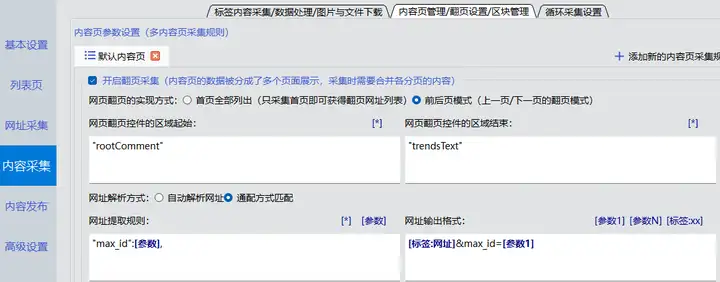
翻页采集
二级评论至此,实现了基本的采集规则,但是二级评论并没有采集到,我们现在拼接出二级评论的采集地址。
可以看出,如果回复数大于零,则说明有二级地址;否则二级地址为空。
添加标签二级评论地址,使用标签组合方式提取,提取规则为[标签:回复数]。标签数据二次处理:
- 字符串替换:0替换为空;
- 添加内容前后缀:后缀为[标签:原始网址],勾上“内容为空时,不添加前后缀”;
- 字符串替换:
- http替换为http,目的是去掉回复数的字符串内容;
- 字符串替换:count=10替换为count=20;
- 字符串替换:&id=
- &替换为&id=[标签:评论ID]&fetch_level=1&。
添加标签原始网址,数据来源为从网址中提取,提取规则为字符串截取,起始和结束字符串都为空。
内容发布切换到“发布到文件”管理器。
添加一个发布配置,名称为“微博评论地址列表”。其模板文件内容如下:
$$$[标签:二级评论地址]$$$
此模板将二级评论地址输出到此文件中,一行一个地址。
添加一个发布配置,名称为“微博评论内容”。其模板文件内容如下:
回复者ID,回复者昵称,回复数,时间,楼层,评论ID,地域类型,地域,内容,HTML内容,点赞数$$$[标签:回复者ID],[标签:回复者昵称],[标签:回复数],[标签:时间],[标签:楼层],[标签:评论ID],[标签:地域类型],[标签:地域],[标签:内容],[标签:HTML内容],[标签:点赞数]$$$
文件编码为GBK。因为csv文件是使用Excel打开,而Microsoft Excel在中文系统中默认使用GBK编码,如果模板设置为UTF-8编码,则打开乱码。也可以使用VSCode打开csv格式的文件,需要安装插件,就可以预览csv文件的表格。
此模板将评论内容保存到csv文件中。如果不清楚如何生成这样的模板,可以点击按钮“自动生成模板文件”,然后选择指定采集规则中要导出的标签,即可。
切换到采集规则编辑窗口的“内容发布”页面。添加两个“发布到文件”的通道,并分别选中上面两个发布配置。设置好之后,可以点击“测试发布”。
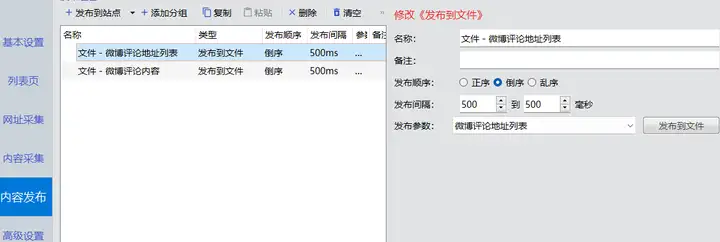
内容发布
二级评论的内容采集复制上面的采集规则,并命名为“新浪微博评论采集2”。
修改列表页的网址源,删除原先的地址,添加一个文件源,并设置自动解析。自动解析时,会按换行自动提取网址列表。勾上“列表页网址即为内容页网址”。
修改“内容发布”。去掉二级评论地址的发布通道,只保留发布评论内容的通道,即可。
至此,完成微博评论的采集工作。
AI情绪分析应用市场中有集成了几个主要云服务器商的自然语言处理AI情感分析的插件,可以下载导入后,添加到标签数据二次处理的插件处理中。调用后输出“负面”、“正面”、“中性”的情绪判断。
由于该功能在各云服务器商都是收费项目,这里就不具体演示了。如需要的话,您也可以添加自己的情感分析插件。
至此,就实现了微博评论的采集。




 发表于 2023-3-23 18:35:15
发表于 2023-3-23 18:35:15